
Master student @ Fudan University
lizhaowei126@gmail.com
# About Me
Hi! I am a final year M.S. student at Fudan University. Currently, I am interning at Bytedance.
My research interest focuses on Multi-Modal Large Language Models and Multi-Modal Agents.
I expect to graduate with a master's degree in June 2025. I'm open to academic collaboration opportunities. Please feel free to contact me by lizhaowei126@gmail.com if you are interested!
# News
[2024.11] We released TinyGrouningGPT, a lightweight large language model with fine-grained visual understanding ablity.
[2024.9] Our SpeechAlign is accepted to NeurIPS 2024!
[2024.8] We released UnifiedMLLM, a large language model that models multi-modal, multi-tasks in a unified representation.
[2024.5] We released QCRD, a general method to distilling contrastive rationale knowledge from LLMs into small language models.
[2024.5] Our GroundingGPT is accepted to ACL 2024! See you in Thailand!
[2024.4] We released SpeechAlign, the first to apply RLHF to align speech language models with human preferences!
[2024.1] We released GroundingGPT, the first end-to-edn multi-modal grounding model.
[2024.1] We released SpeechAgents, the first multi-modal multi-agent system.
#Research
(*: Equal contribution)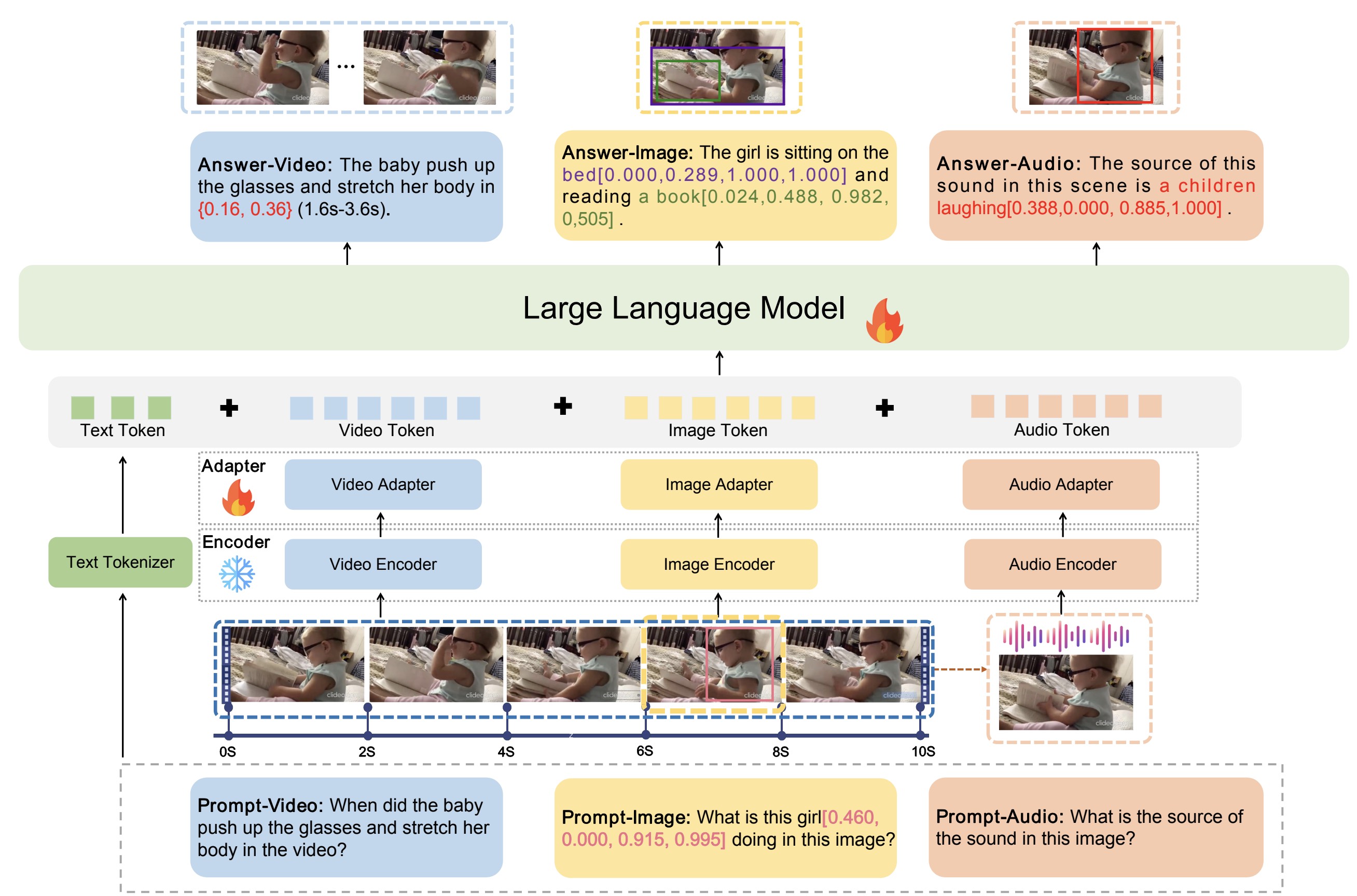
GroundingGPT: Language-Enhanced Multi-modal Grounding Model
Zhaowei Li, Qi Xu, Dong Zhang, Hang Song, Yiqing Cai, Qi Qi, Ran Zhou, Junting Pan, Zefeng Li, Van Tu Vu, Zhida Huang, Tao Wang

GroundingGPT is the first end-to-end large language model that supports multimodal grounding and understanding tasks.
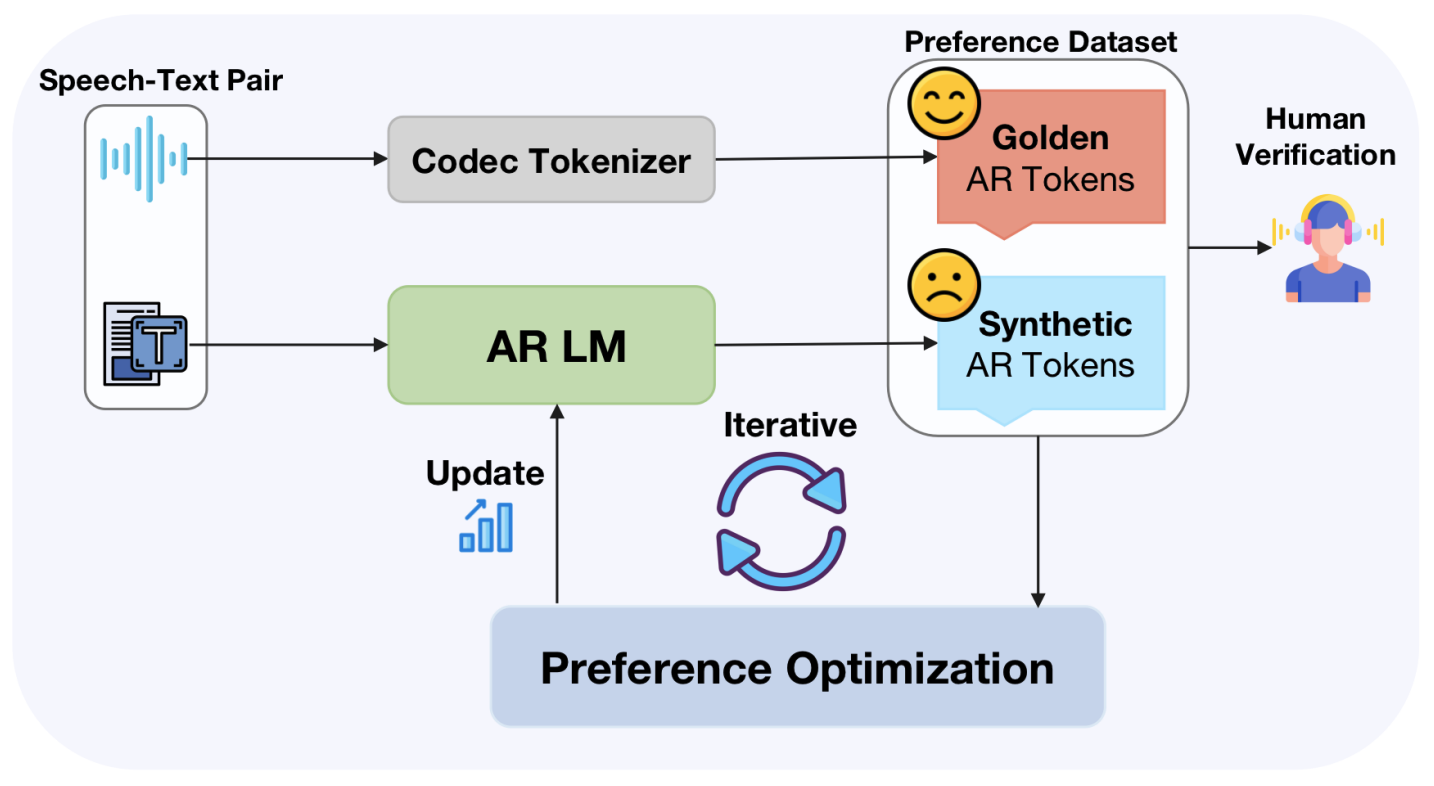
SpeechAlign: Aligning Speech Generation to Human Preferences
Dong Zhang*, Zhaowei Li*, Shimin Li, Xin Zhang, Pengyu Wang, Yaqian Zhou, Xipeng Qiu
[NeurIPS 2024]
[code 
SpeechAlign is the first to applys RLHF to align speech language models with human preferences and proposes an effective iterative self-improvement strategy that converts weak speech language models to stronger ones.
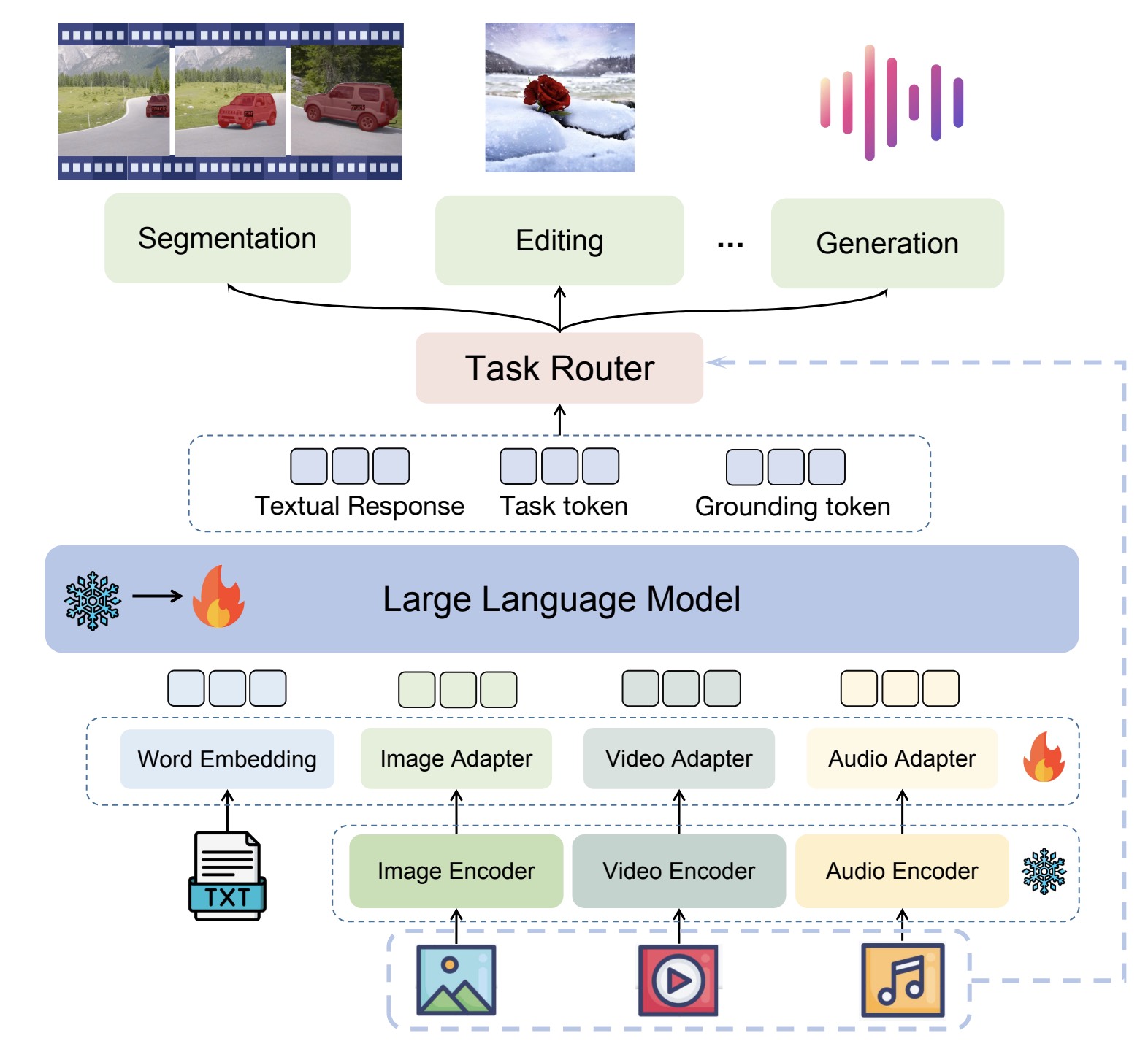
UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model
Zhaowei Li, Wei Wang, YiQing Cai, Xu Qi, Pengyu Wang, Dong Zhang, Hang Song, Botian Jiang, Zhida Huang, Tao Wang

UnifiedMLLM is a large language model that models multi-modal, multi-tasks in a unified representation.
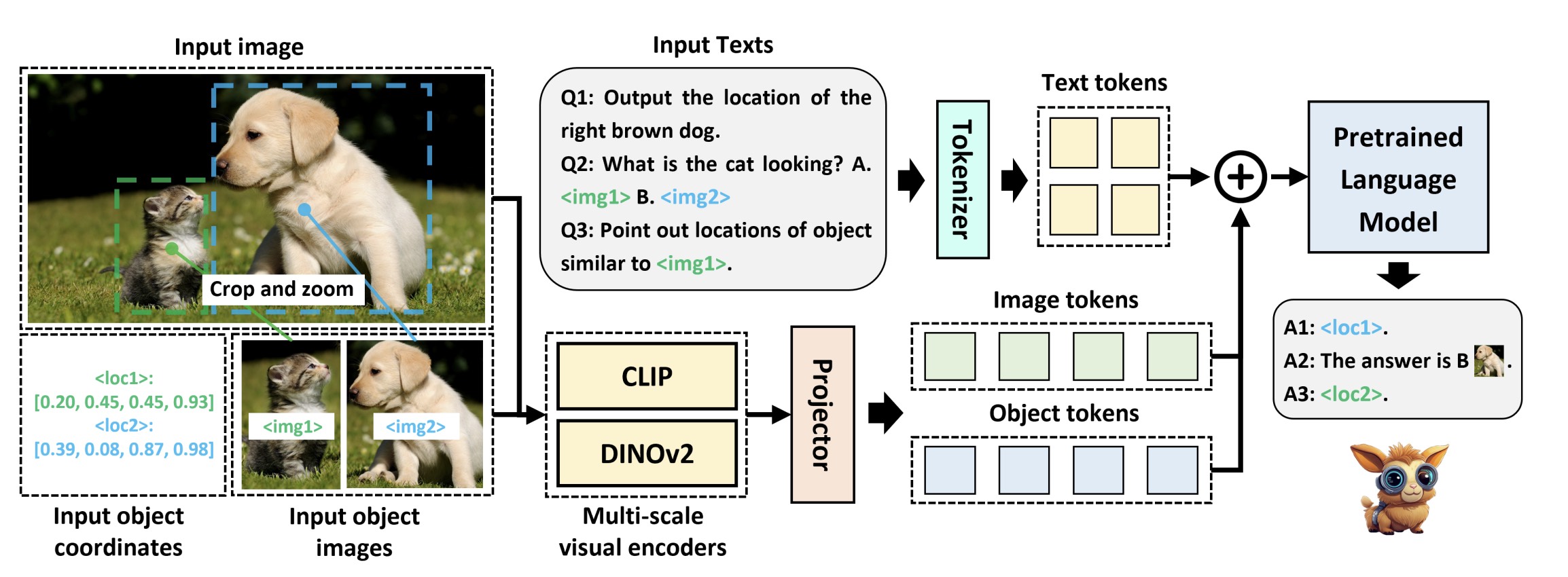
Advancing Fine-Grained Visual Understanding with Multi-Scale Alignment in Multi-Modal Models
Wei Wang*, Zhaowei Li*, Qi Xu, Linfeng Li, Yiqing Cai, Botian Jiang, Hang Song, Xincan Hu, Pengyu Wang, Li Xiao
[Preprint]
TinyGroundingGPT is an effective and efficient large language model with advanced fine-grained visual understanding ablity.

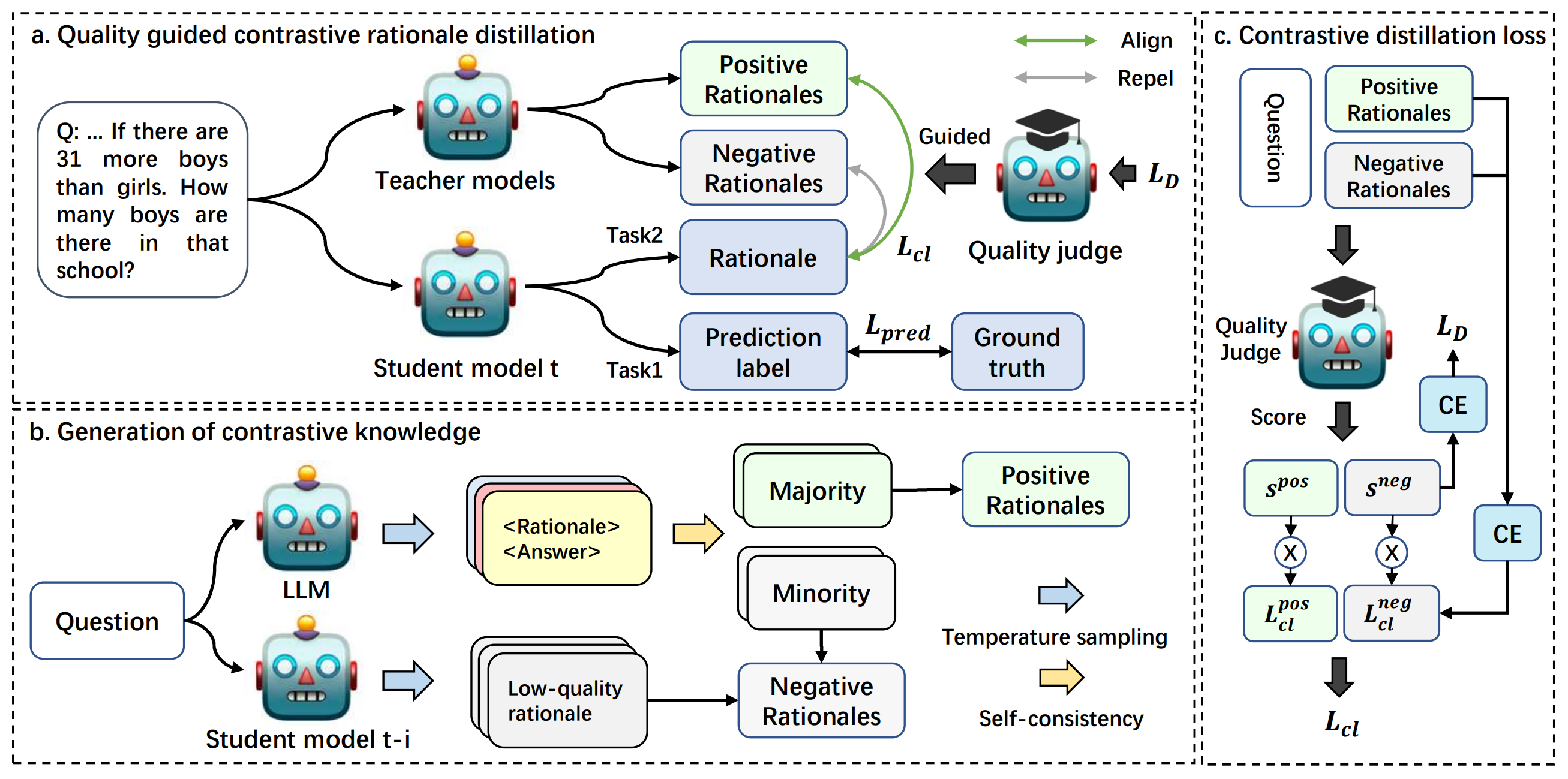
QCRD: Quality-guided Contrastive Rationale Distillation for Large Language Models
Wei Wang, Zhaowei Li, Qi Xu, Yiqing Cai, Hang Song, Qi Qi, Ran Zhou, Zhida Huang, Tao Wang, Li Xiao
[Preprint]
QCRD is a general method to distilling contrastive rationale knowledge from LLMs into small language models.
#Full Publications
#2024
GroundingGPT:Language Enhanced Multi-modal Grounding Model
Zhaowei Li, Qi Xu, Dong Zhang, Hang Song, Yiqing Cai, Qi Qi, Ran Zhou, Junting Pan, Zefeng Li, Van Tu Vu, Zhida Huang, Tao Wang.
ACL 2024SpeechAlign: Aligning Speech Generation to Human Preferences
Dong Zhang*, Zhaowei Li*, Shimin Li, Xin Zhang, Pengyu Wang, Yaqian Zhou, Xipeng Qiu.
NeurIPS 2024UnifiedMLLM: Enabling Unified Representation for Multi-modal Multi-tasks With Large Language Model
Zhaowei Li, Wei Wang, YiQing Cai, Xu Qi, Pengyu Wang, Dong Zhang, Hang Song, Botian Jiang, Zhida Huang, Tao Wang.
PreprintAdvancing Fine-Grained Visual Understanding with Multi-Scale Alignment in Multi-Modal Models
Wei Wang*, Zhaowei Li*, Qi Xu, Linfeng Li, Yiqing Cai, Botian Jiang, Hang Song, Xincan Hu, Pengyu Wang, Li Xiao.
PreprintSpeechAgents: Human-Communication Simulation with Multi-Modal Multi-Agent Systems
Dong Zhang, Zhaowei Li, Pengyu Wang, Xin Zhang, Yaqian Zhou, Xipeng Qiu.
PreprintQCRD: Quality-guided Contrastive Rationale Distillation for Large Language Models
Wei Wang, Zhaowei Li, Qi Xu, Yiqing Cai, Hang Song, Qi Qi, Ran Zhou, Zhida Huang, Tao Wang, Li Xiao.
PreprintUnderstanding the role of LLMs in multi-modal evaluation benchmarks
Botian Jiang, Lei Li, Xiaonan Li, Zhaowei Li, Xiaochong Feng, Lingpeng Kong, Qi Liu, Xipeng Qiu.
Preprint
# Education
Fudan University Sept 2022 - Jun 2025
M.S. in Electronic EngineeringFudan University Sept 2018 - Jun 2022
B.S. in Electronic Engineering
# Internship
Bytedance E-commerce Jul 2023 - Now
Research on multi-modal large language model